


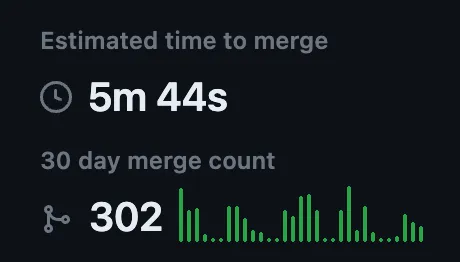
We are truly obsessed with speed — we code, we measure, and if things aren’t fast enough, we code them again. This ability to iterate quickly is the secret sauce behind most of our innovations and ability to respond to customer feedback.
The secret ingredient? Our rapid deployment strategy. We consistently deploy more than 10 times, and it's not uncommon to have a 15-deployment day. We don’t stop on Fridays, and people often deploy on a weekend if they want to get a fix (or a feature) out the door before Mondays. In effect, it feels like we are working directly in production at all times. This feeling is built into our culture, and architected in our tooling.
In this post, I am going to talk about how we’ve been able to sustain such a fast speed of iteration with our deployment strategy. I’ll go over a couple of our key principles, such as Day 1 Deploys and PR Reviews and for each principle, we’ll discuss the technology and process decisions we’ve made that made it possible to turn the idea into reality.
Day 1 deploys
We make starting up Felt as easy as possible. Whenever a new engineer starts, we want them to be able to deploy a small change on their first day. It allows the new hire (or contractor) to feel connected to the product and instills them with our ethos of fast iteration.
On the technology side, Day 1 Deploys means that the application has to be easy to get started on. We’ve really paid attention to our README and made it as foolproof as possible. So far, all our new hires have been able to get the app up and running in less than 25 minutes or so, and most of that is really waiting on compilations of various tools.
On the process side, we hold the hiring managers accountable for this goal — they need to have quick wins ready to go before someone starts, and be ready on Day 1 to hold the new hire’s hand, if needed, to get their code up and running.
Review applications
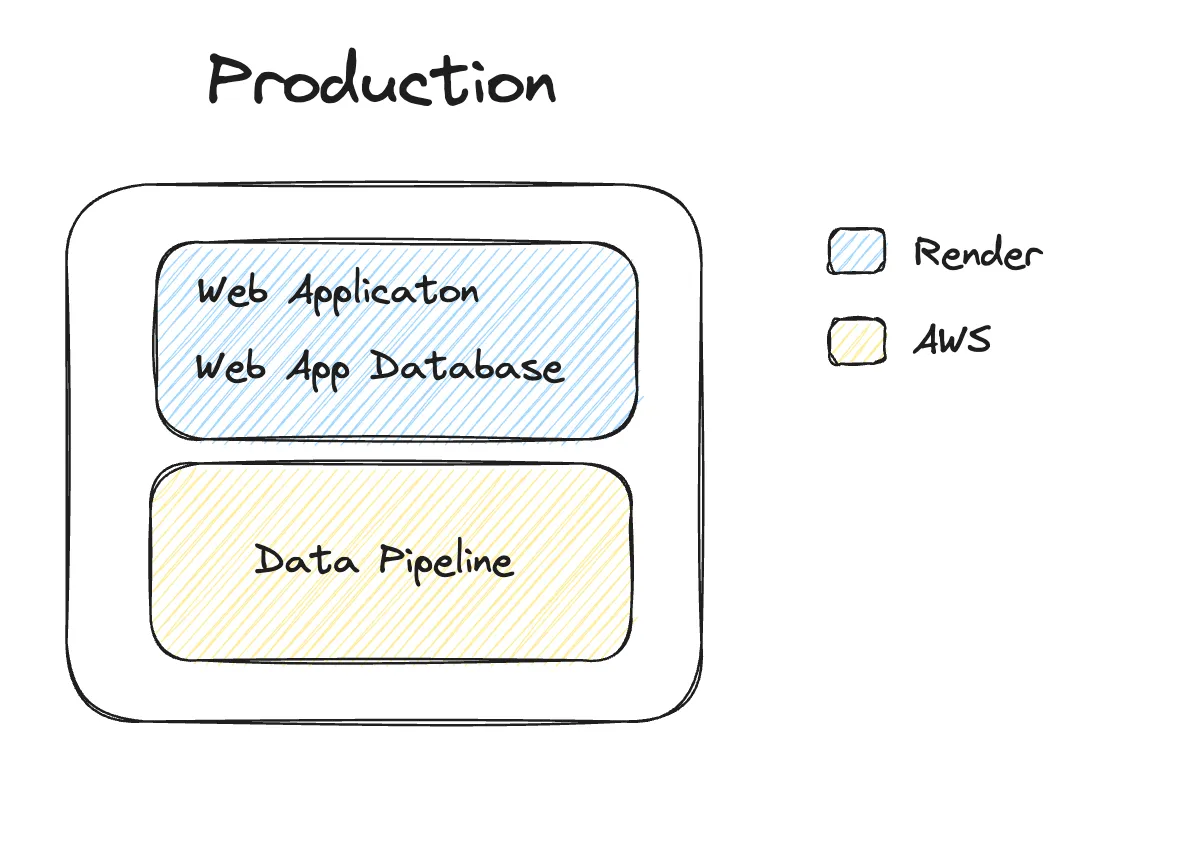
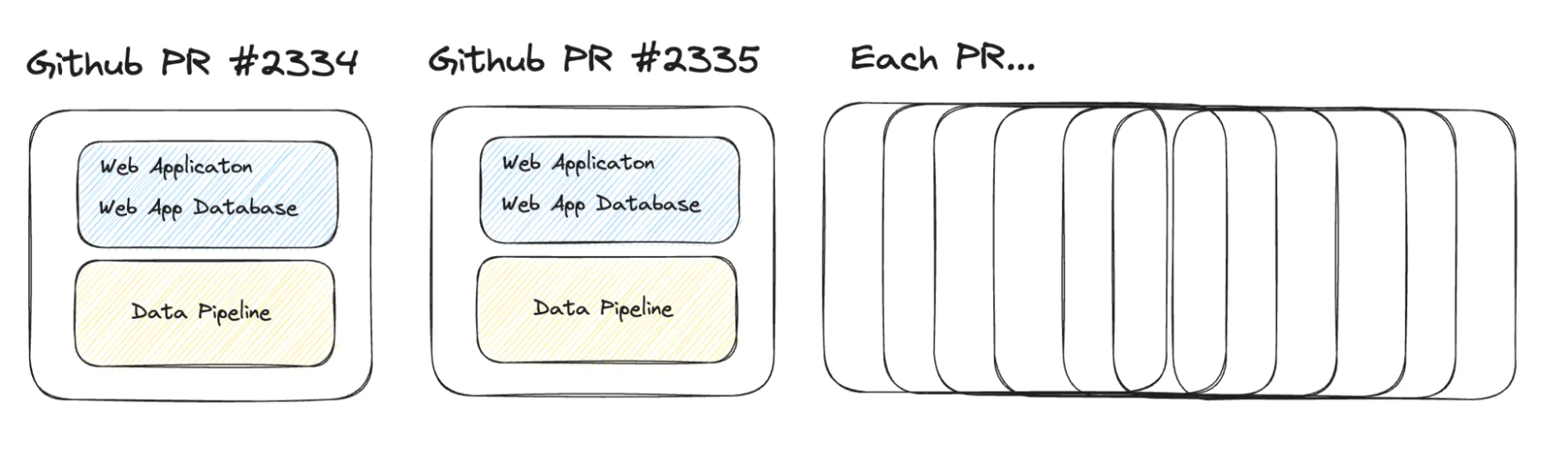
Every pull request is a standalone Felt infrastructure. Instead of fighting over a single staging environment, we make every single change, no matter how small, to become a full-fledged Felt service. Every single pull request gets their isolated environment with its own database, frontend, and backend. This allows a unique way of product testing and development — instead of arguing the benefits of a certain UI interaction compared to another, we’ll build both of them and test them side by side.
Most of this is enabled by using Render’s Pull Request Environments via Blueprints — we use a declarative format to describe our application servers and our database, and create clones of it for each PR (and Production).
Compare Felt using AI






.webp)


.webp)

