In Part 1 of the post describing how we switched from SVG to Canvas, we talked about how we render the elements in a performant way. But rendering performance was just one thing we aimed to achieve with the switchover. The other was a better way of writing our interaction-handling code.
In this part, we’re going to talk about how we wrote a new interaction handling system from the ground up, covering:
- the problems with our React approach
- what we wanted to achieve with the new system
- how it simplified our existing interaction code
- how we solved a long-standing wishlist item that we couldn’t do with React
Interacting with SVGs in React
As a quick reminder, here’s a simplified example of how our React components were structured in the SVG world:
Visually, it’s arranged roughly like this:
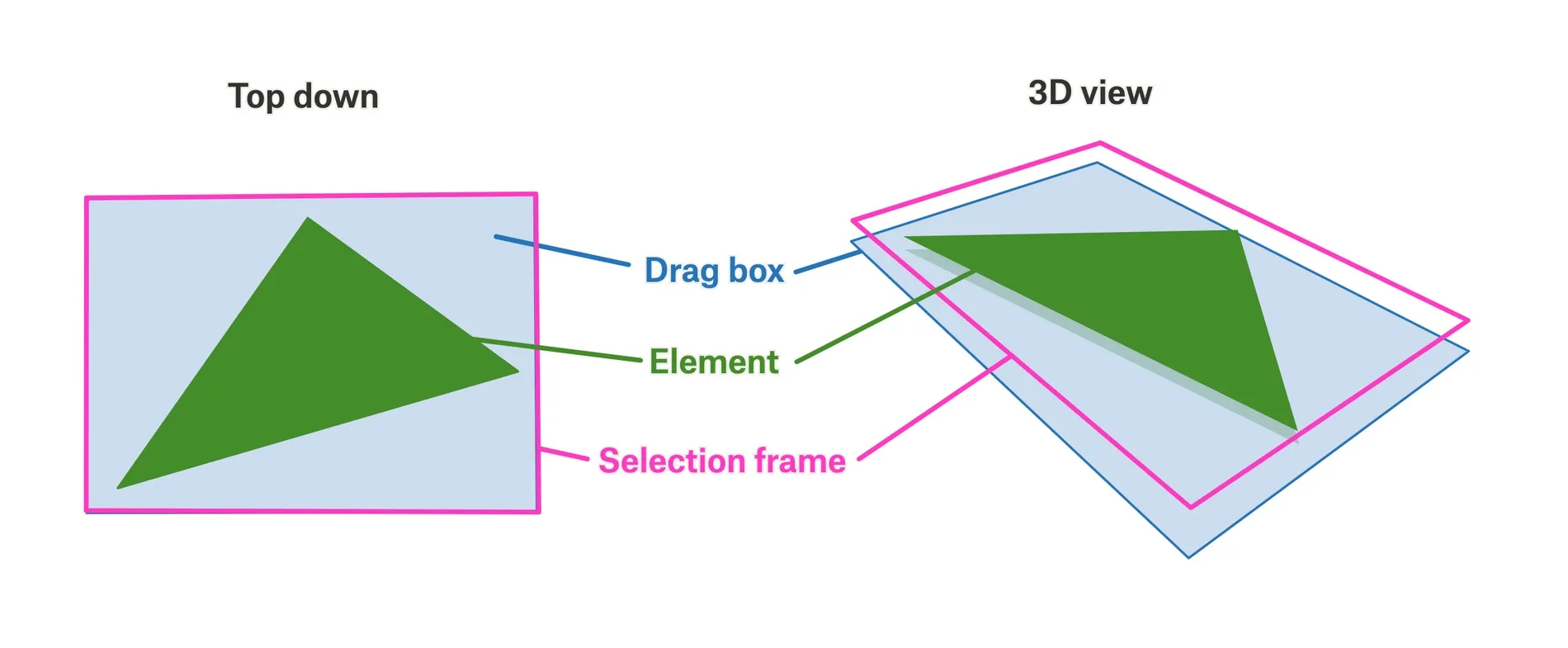
The different parts are:
- The <p-inline>Element<p-inline> itself (green)
- The <p-inline>SelectionFrame<p-inline> which shows when the element is selected (pink)
- The <p-inline>DragBox<p-inline>, which is a transparent DOM element that lets you drag the element when selected, but is “behind” other elements so they can be selected on top (blue)
In the SVG world, we use CSS <p-inline>z-index<p-inline> to place the DragBox at the back and the SelectionFrame at the front.
With SVGs we get a lot of useful stuff “for free” which made it easy for us to get started developing Felt:
- the mouse only hits SVG elements inside their painted region, which is great for the <p-inline>Element<p-inline> portion
- we could use things like <p-inline>pointer-events<p-inline> to disable certain interactions at certain times
- because the interaction code and rendering code are together in a React component, simply not rendering the React component also disables the interactions.
However, there are also some limitations of that model, which give us some problems.
Performance
Yes, we already covered performance last time, but it’s worth mentioning again with respect to interactions.
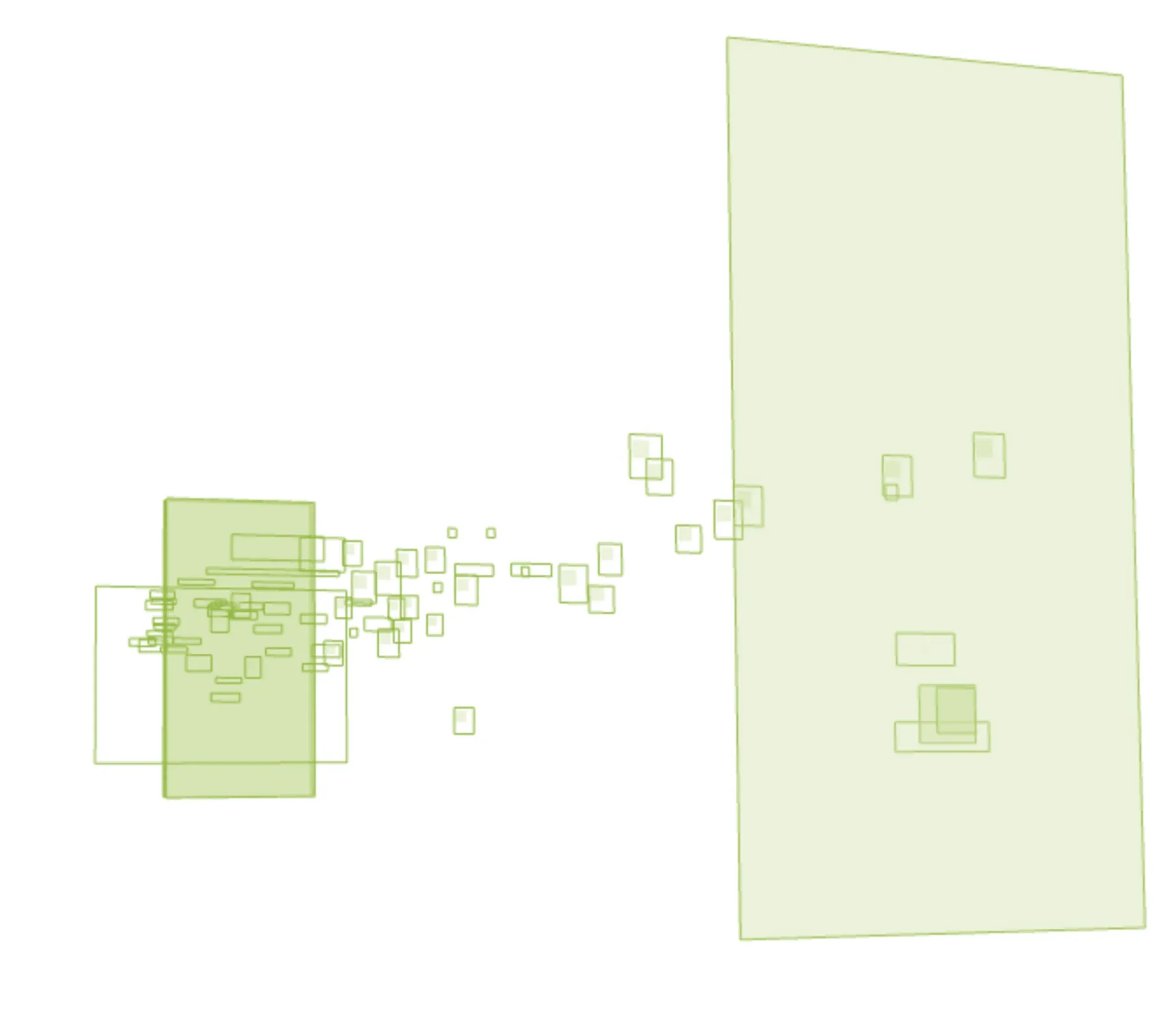
Having every element produce a whole load of DOM elements for React to manage becomes a problem for performance when every element attaches event handlers, has to manage their lifecycles, observe state, etc., etc.
Here’s an example of the layers created in the DOM for a map with just a handful of elements.
Interactivity limitations
With our SVG renderer, each element managed its own interactions, which made it impossible to drag elements that were underneath other elements. This is a surprisingly common when making complex maps.
In the example below, we have the red polygon selected, with some yellow text over the top of it.
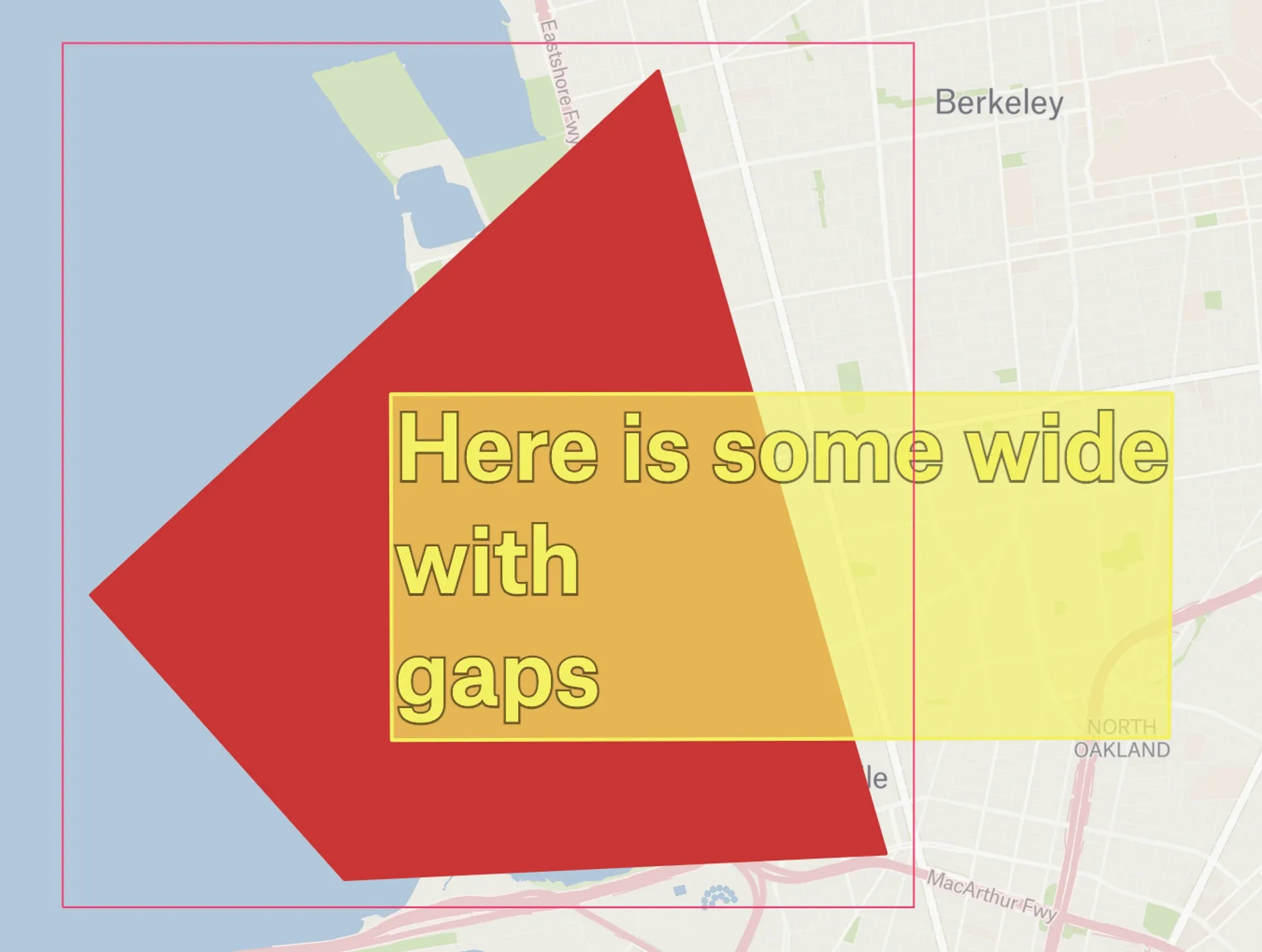
Now, say we want to drag the red polygon – but with the text taking up so much space it’s very easy to accidentally drag the text instead, which is really irritating!
This was a very longstanding bug, which was very difficult to solve with DOM elements. With each element having a self-centered view of the world, having it know about every other element too would introduce a lot of extra complexity!
Maintainability
Another problem that affected us was our ability to fix bugs and make sure they stayed fixed.
Although we have a comprehensive suite of automated end-to-end Playwright tests, we can’t reasonably cover every single combination of interactions, so we rely on the code structure and cleanliness as a way to reduce bugs.
However, with every element attaching its own interactions, there is a tendency for every interaction to know about every other, checking if it should be enabled or not. This leads to code that looks a bit like this:
As you can see, we’re checking lots of other features to see if they’re “active” before continuing with our own work.
Another maintainability issue is the proliferation of <p-inline>event.stopPropagation()<p-inline> calls in the code. These are to stop events bubbling up through the complex DOM structure and allowing other components to handle events.
We also have a few places where we have awkward <p-inline>setTimeout()<p-inline> calls where we can’t actually stop the event reaching another part of the code, so instead have to signal that we’ve handled it and that someone else shouldn’t.
This type of complexity explodes as more features are added, and that’s not what we want to be dealing with – we want to be shipping the features our users are asking for!
What we wanted from the new world
Taking all our pain points into consideration, we set some goals for the new system.
- Features should not need to know about each other
- We should be able to write precise, complex interactions with minimum fuss
- Concepts and code should remain simple and not intertwined
- Interactions should be performant
The new system: per-state InteractionHandlers
OK, so the name is quite generic and doesn’t tell you much, but I’ll do my best to explain.
The general idea is this: there are a lot of different things you can do in Felt, but at any given time, the number of things you can do is limited. If we can therefore define which interactions are active at any given time, and also manage the flow of events through the handlers we should be in a good place.
Here, you can see an example of how our InteractionHandlers are set up for a given app mode.
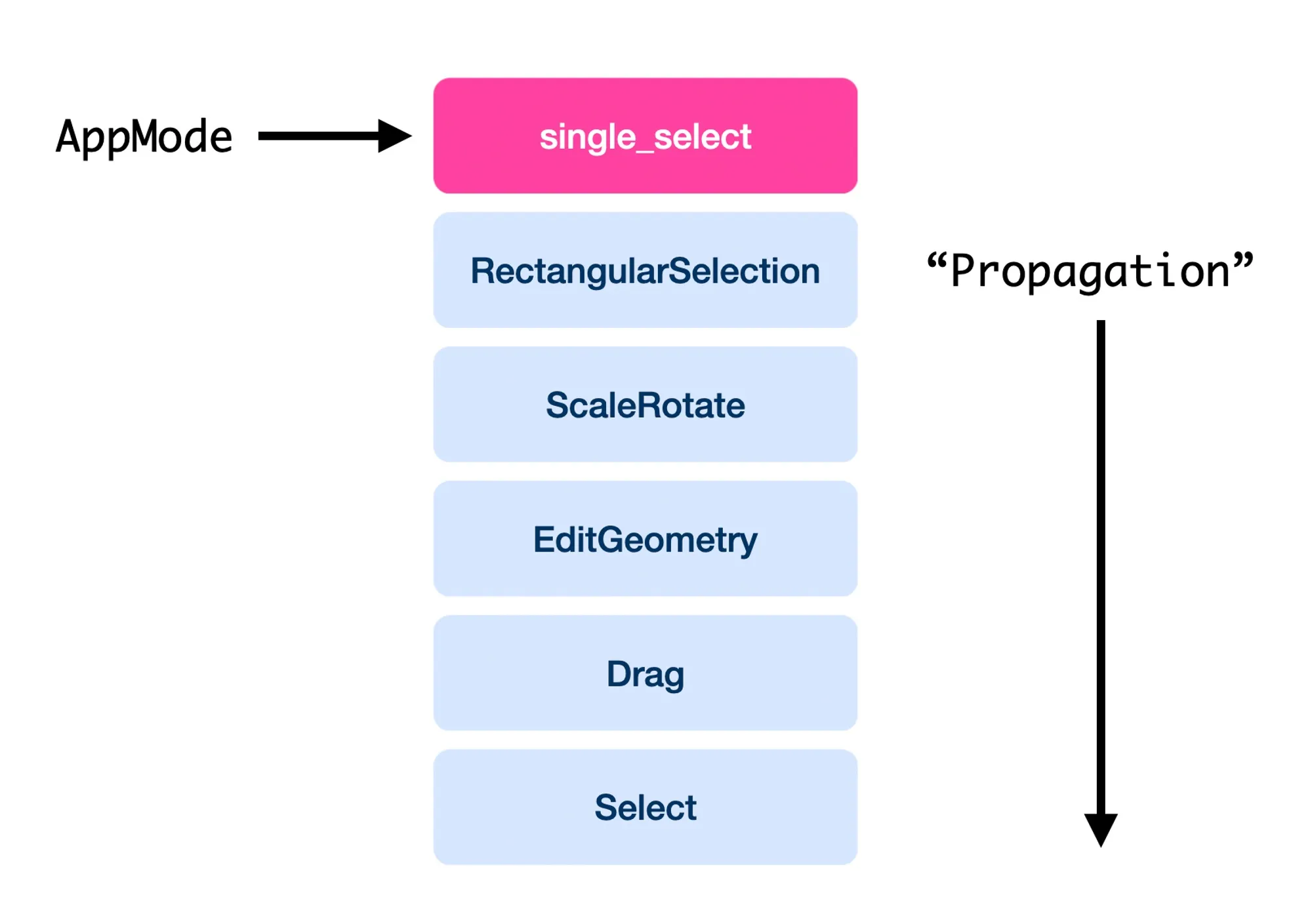
As you can see, for a given <p-inline>AppMode<p-inline> there is a prioritized list of handlers that are active. Which ones are active depends on the <p-inline>AppMode<p-inline> and is specified in a <p-inline>handlerMap<p-inline>.
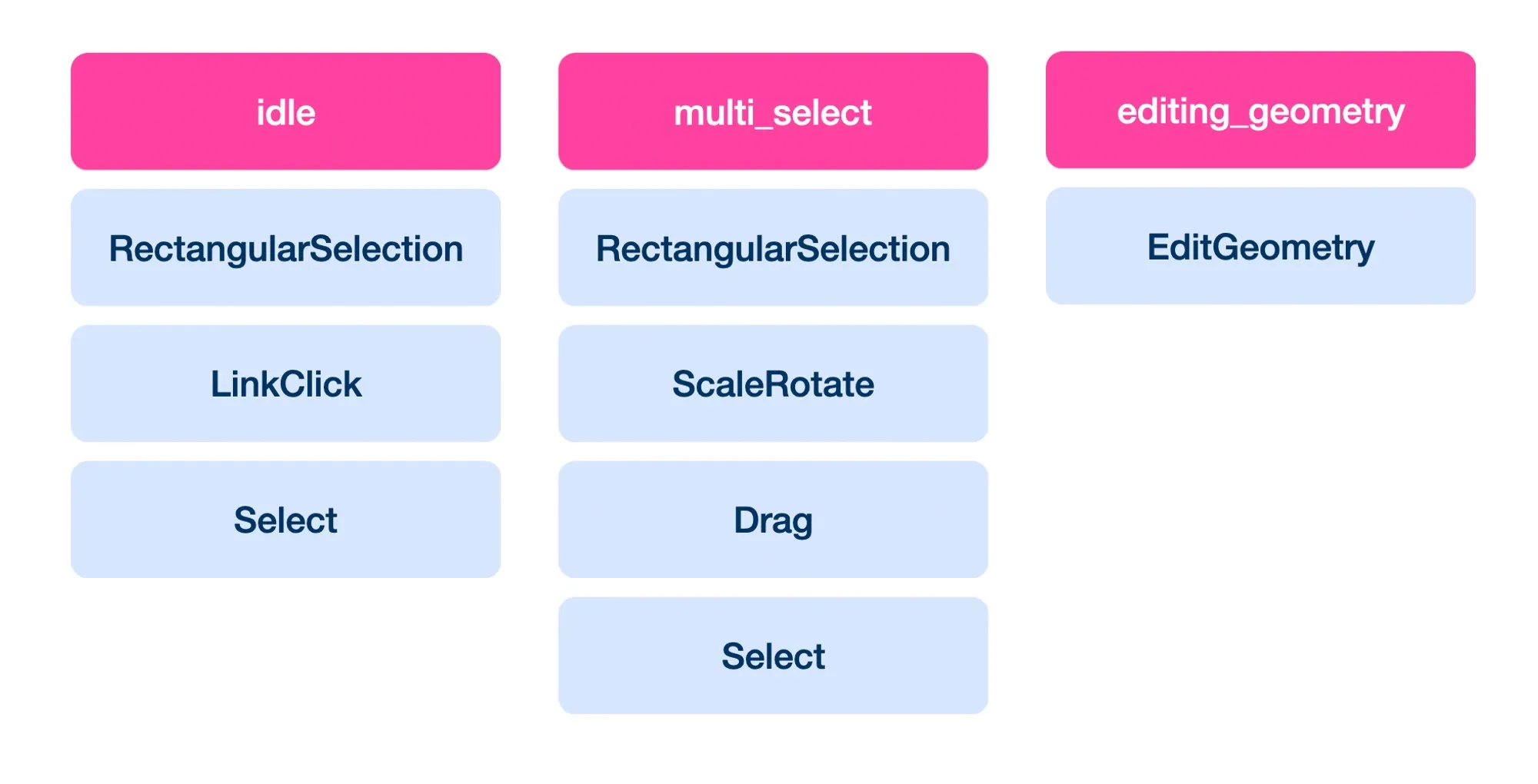
The <p-inline>InteractionManager<p-inline> is responsible for:
- starting and stopping each handler when it becomes active or inactive
- converting DOM events to <p-inline>InteractionHandler<p-inline> events.
- For instance, we have <p-inline>onDragStart<p-inline> which is synthesized from raw <p-inline>onPointerDown<p-inline> and <p-inline>onPointerMove<p-inline> events
- We also are able to stop <p-inline>onClick<p-inline> from being called if the mouse is dragged far enough
- calling each relevant <p-inline>InteractionHandler<p-inline> with each event
- dealing with the <p-inline>InteractionHandler<p-inline> responses
Each <p-inline>InteractionHandler<p-inline> is responsible for:
- managing its own state
- resetting or clearing that state as appropriate when the handler is started or stopped
- responding to the events appropriately, especially:
- requesting no further propagation to any other handlers
- requesting no further propagation to any future events (e.g. to terminate a <p-inline>onPointerDown -> onPointerUp -> onClick<p-inline> sequence in the middle)
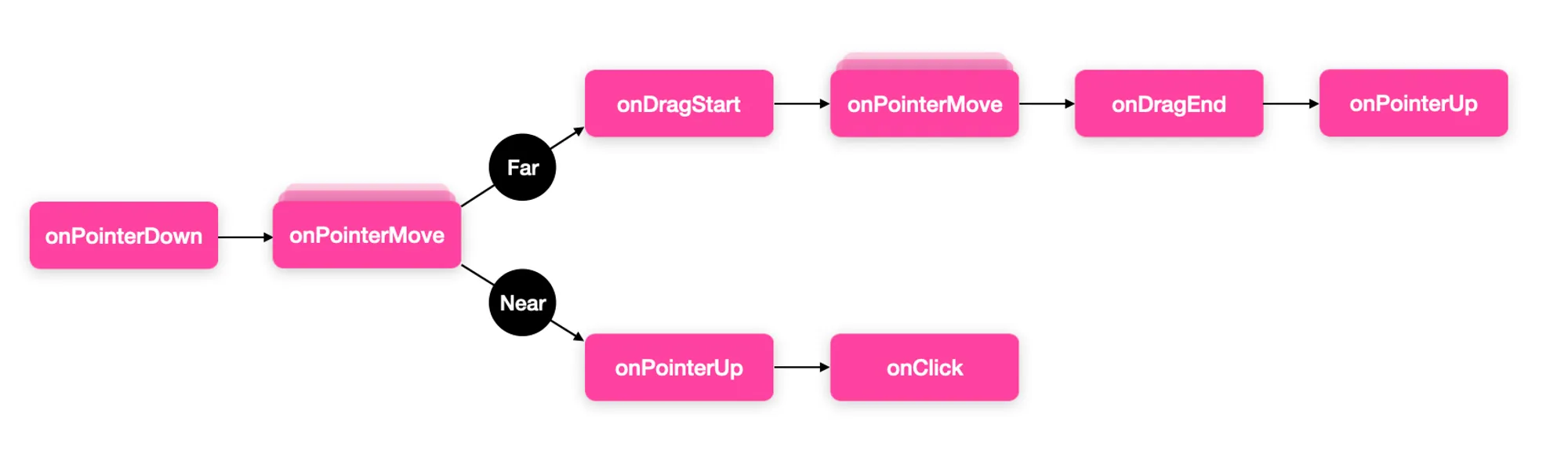
Here is the full sequence of events that an <p-inline>InteractionHandler<p-inline> can process, with the ability to break the chain at any point, and prevent other handlers in the stack from being called.
These <p-inline>InteractionHandlers<p-inline> are just objects satisfying a specific TypeScript interface. They’re not coupled to React or hooks or anything like that, which feels quite freeing, honestly. There’s no worrying about stale closures or dependencies or hooks rules - it really is just TypeScript.
This setup has some nice properties that speak to our goals. I’ll take each in turn and describe how it helps us.
Goal 1: Interactions should be decoupled from each other
Each interaction handler has no knowledge of any other. The knowledge about how to prevent “collisions” in interactions resides with the map of handlers and the manager.
There is no code in this system that has to check if other features are “busy” in order to decide to act or not. That “priority” is encoded in the map of app modes to handlers, and then each subsystem works independently.
One particularly nice aspect of this system is that key presses follow the same flow as pointer events, which is not how things work in the DOM. In the DOM, you usually bind key handlers globally, and pointer events per element. But here, we get all the benefits of stopping propagation centrally, which is a real help for adding keyboard shortcuts and modifier keys.
Goal 2: Interactions should be performant
Because there is only one handler per feature as opposed to a bunch of handlers per element, there is a lot less allocation of resources.
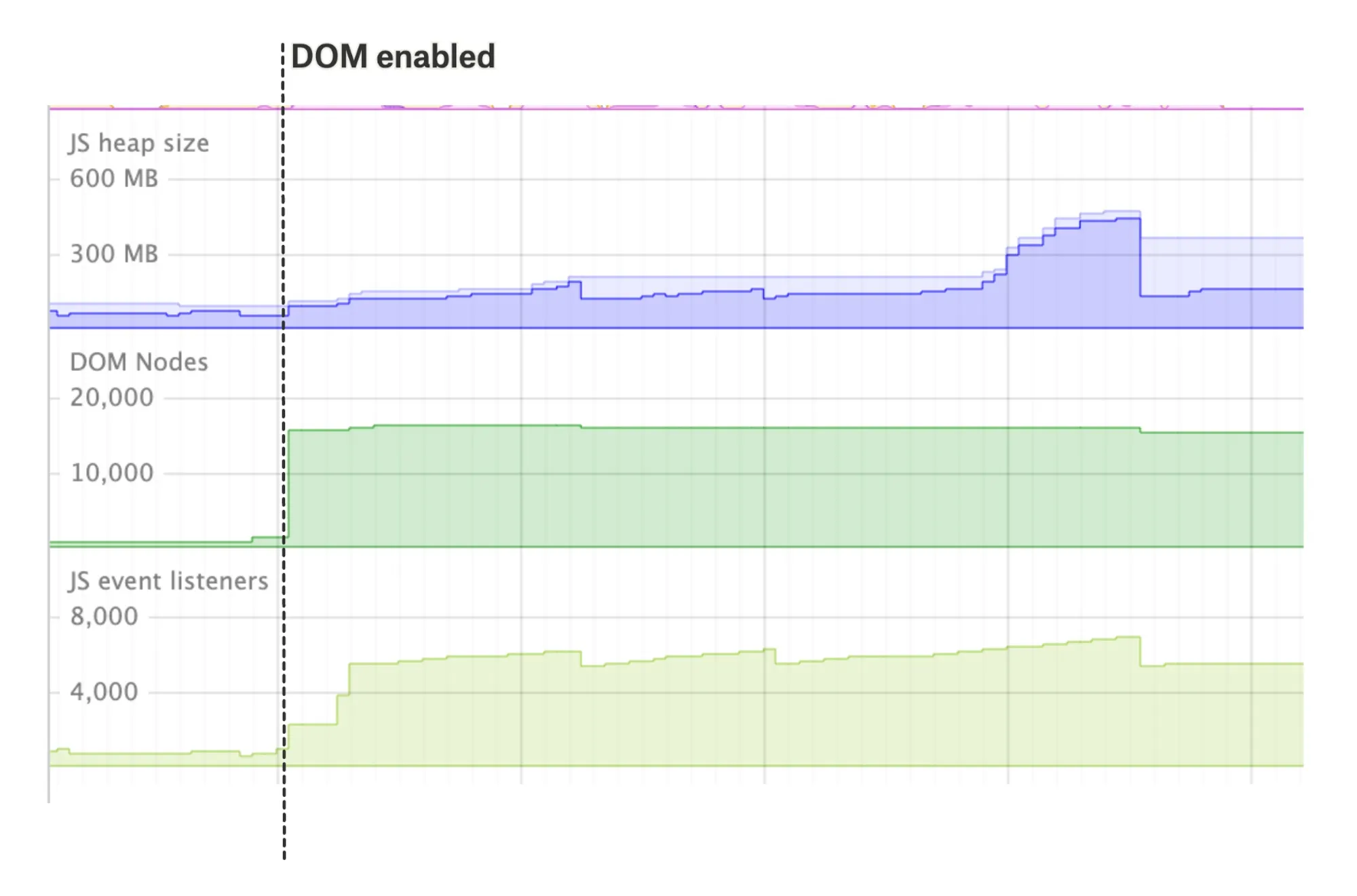
You can see in this Chrome DevTools Performance Monitor trace how the memory usage, DOM Node count and JS event listeners count explodes as we switch from Canvas back to DOM rendering.
Goal 3: Interactions should be decoupled from access control
Access control is now simply a case of writing a different list of interaction handlers for each access level. There’s no longer any <p-inline>isEditor<p-inline> code littered throughout.
Here is a sample of how the available interactions differ between users with edit capabilities and those with just viewer capabilities.

We also have an <p-inline>inert<p-inline> access level, where all interactions are disabled, simply by configuring empty lists of handlers for every possible app state. This would be very fiddly and error-prone to do with the previous system.
Goal 4: Interactions should be decoupled from rendering
None of the interactions depend on a particular rendering system. We can actually use the DOM as a render target with all its pointer events disabled, and use this interaction system on top, which is quite neat!
Aside from being quite fun, we also want this property for the future of Felt. As the gap between map elements and layer features narrows, there’s a strong chance we’ll elect to push all of our rendering of geographic elements into MapLibre to get even more performance, but leave all our app-specific rendering (selection frames, etc.) alone. With this system, we can leave all the interactions completely alone, which makes this possible migration a lot easier.
This is semantically how the app is separated right now.
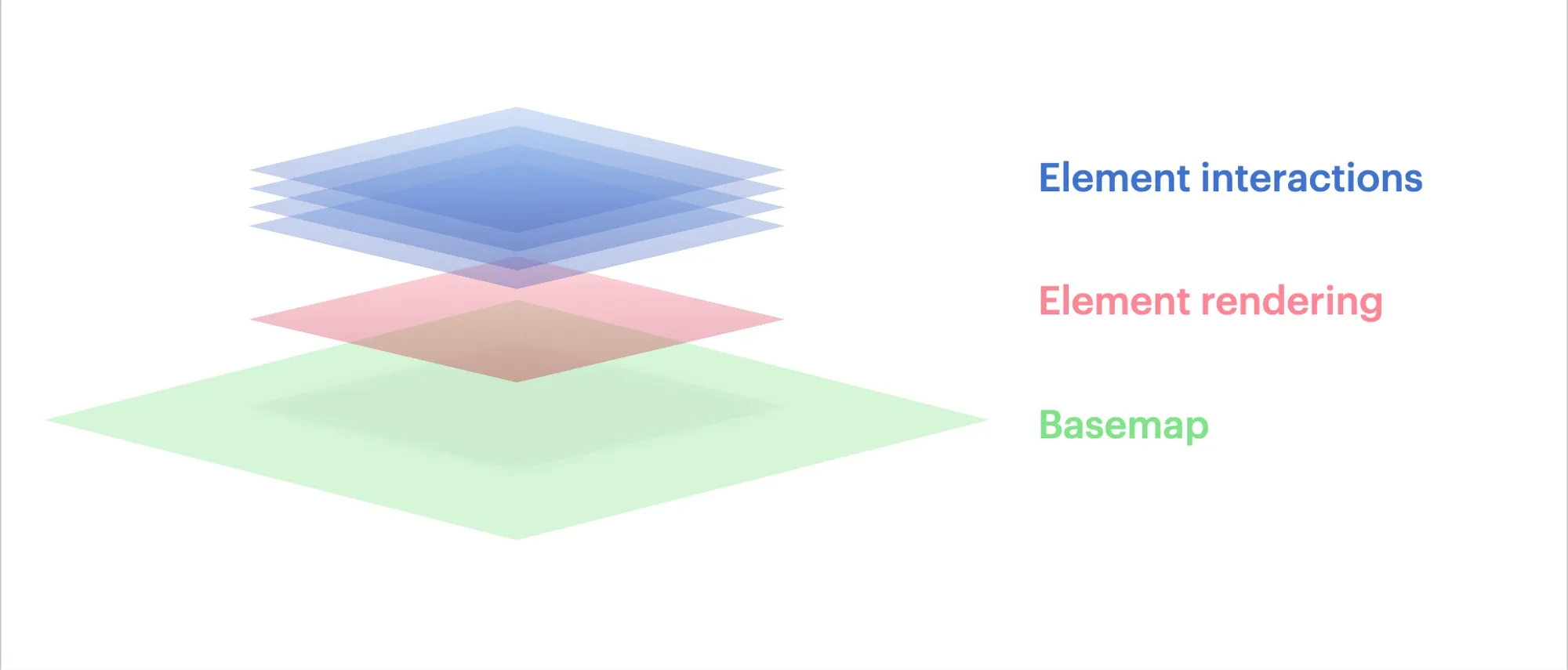
And here’s how we could change that in the future, pushing element rendering down to the same technology as the basemap rendering. All of the interactions are left alone.
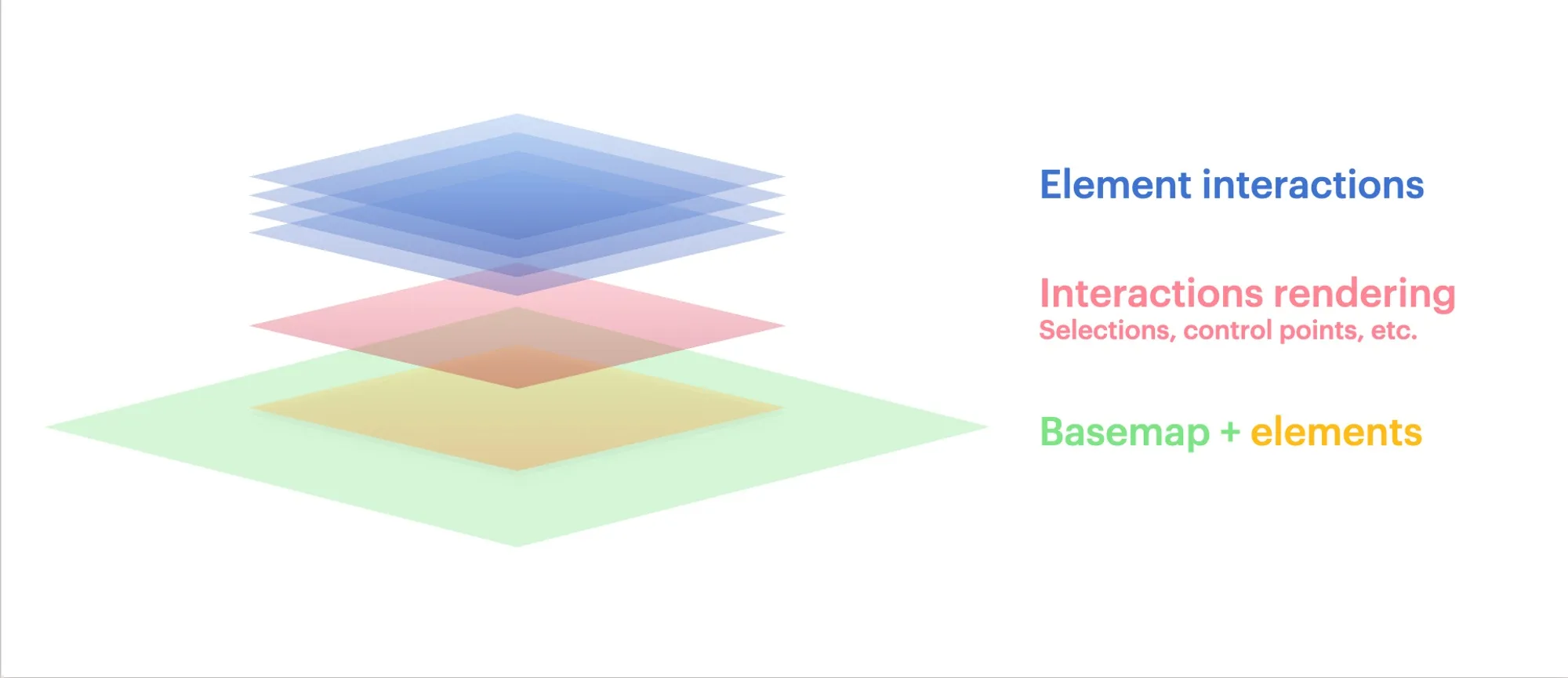
This decoupling means that we don’t have a typical “object model” for the scene like many drawing or graphics systems have. Instead, each interaction handler acts on the whole scene, rather than being tied to an individual element.
Rather than having to deal with figuring out which elements are under the cursor, or which elements are locked, hidden, etc. our <p-inline>InteractionManager<p-inline> also handles all this, then this is passed into the handlers for easy access.
Each handler having an overarching view of the entire scene is what allows us to achieve one of some of our more complex interactions…
Goal 5: Complex interactions should be achievable
One small interaction that we had always wanted to add to Felt had been all but unattainable in the DOM world: being able to drag through unselected elements, but still being able to click them to select.
In the video, you can see that we select the red polygon, which is ordered beneath the white text. Then, we are still able to drag the red polygon through the white text, but also click on the white text to switch the selection to that.
This happens a surprising amount in mapmaking, partly because of the many irregular shapes and large zoom ranges. And when it doesn’t work, it can be really frustrating.
Doing this with an element-centric approach is nigh-on impossible. There’s no way (as far as we know) to say to a DOM element: “receive clicks, but pass-through mousedowns and drags.”
In the behavior-centric approach, this is very straightforward. Because the <p-inline>dragHandler<p-inline> and selectionHandler don’t overlap in the events they handle, there’s really no interference at all.
This is all we need to achieve this with our new system!
OK, there are some hidden details there such as how we get the <p-inline>elementsUnderCursor<p-inline>, and the <p-inline>topElement<p-inline>. There’s a fair bit of supporting code that is out of scope for this post, but for those that are interested, we maintain a spatial index of our elements using rbush which we query for coarse intersections with the cursor before performing more accurate hit tests using Turf.js.
Despite brushing over the details, you can hopefully see the elegance of this approach. By not attaching events to DOM nodes, we don’t have to worry about CSS <p-inline>pointer-events<p-inline>, <p-inline>z-index<p-inline> etc., and can focus on domain-specific code like: “am I starting to drag over an already selected element?”
Trade-offs
While our resulting system is certainly more manageable and with clearer code than the DOM-based solution, it’s not without its difficult parts.
Firstly, it takes a bit of getting used to thinking about interactions from an app-wide context rather than an element-specific one. It means that what can turn out to be easy solutions don’t seem obvious. The “drag-through unselected elements” interaction is a good example. I was so used to thinking about things in terms of elements and layers that I was overcomplicating the solution, until a coworker implemented it in a few lines, succinctly describing it as “click prioritizes z-index, drag prioritizes selection”.
Secondly, the browser does a lot of useful work with SVGs for hit testing. Getting to browser-native levels of performance for intersecting long paths hasn’t been straightforward. We’ve had to do a lot of spatial indexing, pruning and other optimisations in order to be able to quickly determine things like whether the mouse is over a line with 20,000 vertices!
Conclusions
I mentioned this in Part 1, but I wouldn’t recommend undertaking a big change like this without feature flags, performance benchmarks and a good suite of end-to-end tests.
I would, however, definitely recommend considering whether it’s worth taking the leap away from the “default” way of doing things if something doesn’t feel right. While our interaction system isn’t completely novel and draws on a lot of things for inspiration (including the DOM APIs and concepts), it’s certainly a divergence from the norm.
While making the switchover, there were certain bits of functionality missed or forgotten, but fixing issues in this new system has felt a lot easier than fixing bugs in the previous system, and even some of the more fiddly fixes can be implemented cleanly without reaching for hacks.
Hopefully, this new baseline of maintainability, simplicity, and performance will survive all the new features we want to add to Felt for our users in the future.
And that’s what it’s all about, really: making sure we can spend more time focusing on what our users want and make Felt an even better way to work with maps.
Compare Felt using AI






.webp)